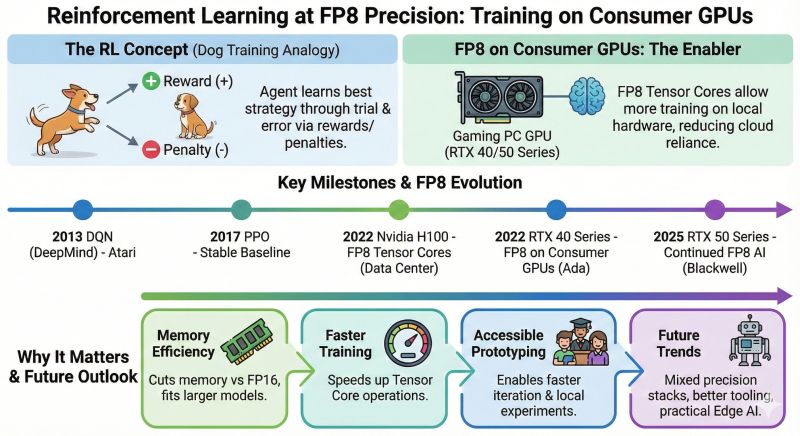
🐾⚡ Reinforcement Learning at FP8 Precision: Training on Consumer GPUs Sometimes we assume that RL needs data-center GPUs to do it, but Do you know that weccan do it on consumer GPUs by the help of F…
1001 viral
AI7 months ago

LinkedIn Content Strategy & Writing Style
Cloud & AI Infrastructure Architect | GPUaaS | NVIDIA AI Stack | Cloud Security & Networking
1 person tracking this creator on ViralBrain
Taher A. Bahashwan positions himself as a technical bridge between high-level AI strategy and the metal, specifically focusing on the hardware-software synergy required for enterprise-scale deployment. His content strategy centers on demystifying the NVIDIA AI stack, moving beyond surface-level hype to provide deep-dives into GPU architecture, memory bandwidth, and the evolution of attention mechanisms. What makes him notable is his ability to translate abstract machine learning concepts into tangible infrastructure requirements, such as comparing GPU selection to logistics fleet management or explaining the cost-saving benefits of PagedAttention. This intersection of architectural consulting and educational transparency allows him to serve as a vital guide for teams navigating the transition from experimental GenAI to production-ready GPUaaS environments.
1.4K
871
5
—
9.8
44
1
🐾⚡ Reinforcement Learning at FP8 Precision: Training on Consumer GPUs Sometimes we assume that RL needs data-center GPUs to do it, but Do you know that weccan do it on consumer GPUs by the help of F…
9.8 posts/week
Posts / Week
0.8 days
Days Between Posts
1
Total Posts Analyzed
HIGH
Posting Frequency
5.4%
Avg Engagement Rate
STABLE
Performance Trend
450
Avg Length (Words)
HIGH
Depth Level
ADVANCED
Expertise Level
8.5/10
Uniqueness Score
YES
Question Usage
0.2%
Response Rate
Writing style breakdown
Professional-explanatory with a strong educational bent.
Conversational but not casual-slangy; aimed at a LinkedIn / tech-business audience.
Highly informative and structured, with light persuasive elements (“Why teams care today”, “Why they dominate right now”).
Uses vivid analogies and simple metaphors to explain advanced AI concepts.
Tone is confident, slightly “teacherly”, but inclusive (“we”, “teams”, “you”).
Technical vocabulary is accurate and contemporary (KV cache, FP8, MoE, context windows, etc.).
Grammar is generally correct but with occasional small imperfections (slight typos, missing articles, minor agreement issues).
No heavy slang, but relaxed phrasing appears (“the game has changed”, “changed everything”, “what is really happening inside”).
Medium-to-high energy, optimistic and forward-looking.
Frequently uses “Where this is heading” / “What’s becoming prominent” / “🔮” sections to signal excitement about the future.
Short, punchy statements.
Contrasts (Traditional ML vs GenAI, Diffusion vs Multimodal, etc.).
Emphasis on impact and applications (“why teams care today”, “why they dominate”).
Everyday analogies near the top of each post (“Think of it like a restaurant kitchen”, “Think of teaching a dog new tricks”, “Think of MLP like a decision-making committee”).
Historical “Origin & Key Milestones” timelines with dates.
Breakout sections about “What X actually does”, “Why teams care”, “Where this is heading”.
What is really happening inside the deep learning and inside the neural networks?
So what is RL?
What’s the NVIDIA stack/frameworks for training/fine-tuning vs inference?
Traditional ML classifies or predicts. GenAI creates.
Transformers changed everything—from translation to chatbots to code generation.
Light storytelling via analogy rather than full narratives; no long personal anecdotes.
Mostly second person (“you hear…”, “If you’re building on NVIDIA today…”, “Do you know that we can do it…”).
Occasionally first person plural “we” to show collaboration or shared assumptions (“Sometimes we assume that RL needs data-center GPUs…”).
Very rare first-person singular “I”; avoids personal stories.
Think of it like a restaurant kitchen.
Let us start with Training/Fine tuning.
Let us check the ‘Enterprise inference-tier GPUs…’
Uses “teams” as the implicit subject frequently (“Why teams care today”, “Why teams care about MLPs today”).
Sign in to unlock the full writing analysis
Free tools to help you write, score, and benchmark in the same style.
Other creators worth studying alongside TAHER A. BAHASHWAN.

Jeff Schwartz
VP of Insights & Impact at Gloat; Work & Workforce Orchestration Platform. Global Researcher, Future of Work; Author, WORK DISRUPTED; Co-author, Workforce Ecosystems, Adjunct Professor Columbia Business School
20 Viral Score

Dan Hockenmaier
CSO at Faire; danhock.com
137 Viral Score

Alex Rechevskiy
I help PMs land $700K+ product roles 🚀 Follow for daily posts on growing your product skills & career 🛎️ Join our exclusive group coaching program for ambitious PMs 👇
10 Viral Score

Lenny Rachitsky
Deeply researched product, growth, and career advice
12 Viral Score

Lily Ray
Founder of Algorythmic | VP, SEO & AI Search at Amsive
44 Viral Score

Eli Schwartz
Author of Product-Led SEO | Strategic SEO/AEO & Growth Advisor/Consultant | Angel Investor| Newsletter Productledseo.com| Please add a note to connection requests.
36 Viral Score
ViralBrain plans, writes, and schedules your LinkedIn content — using official LinkedIn APIs so your account stays safe.
Write like TAHER A. BAHASHWAN.