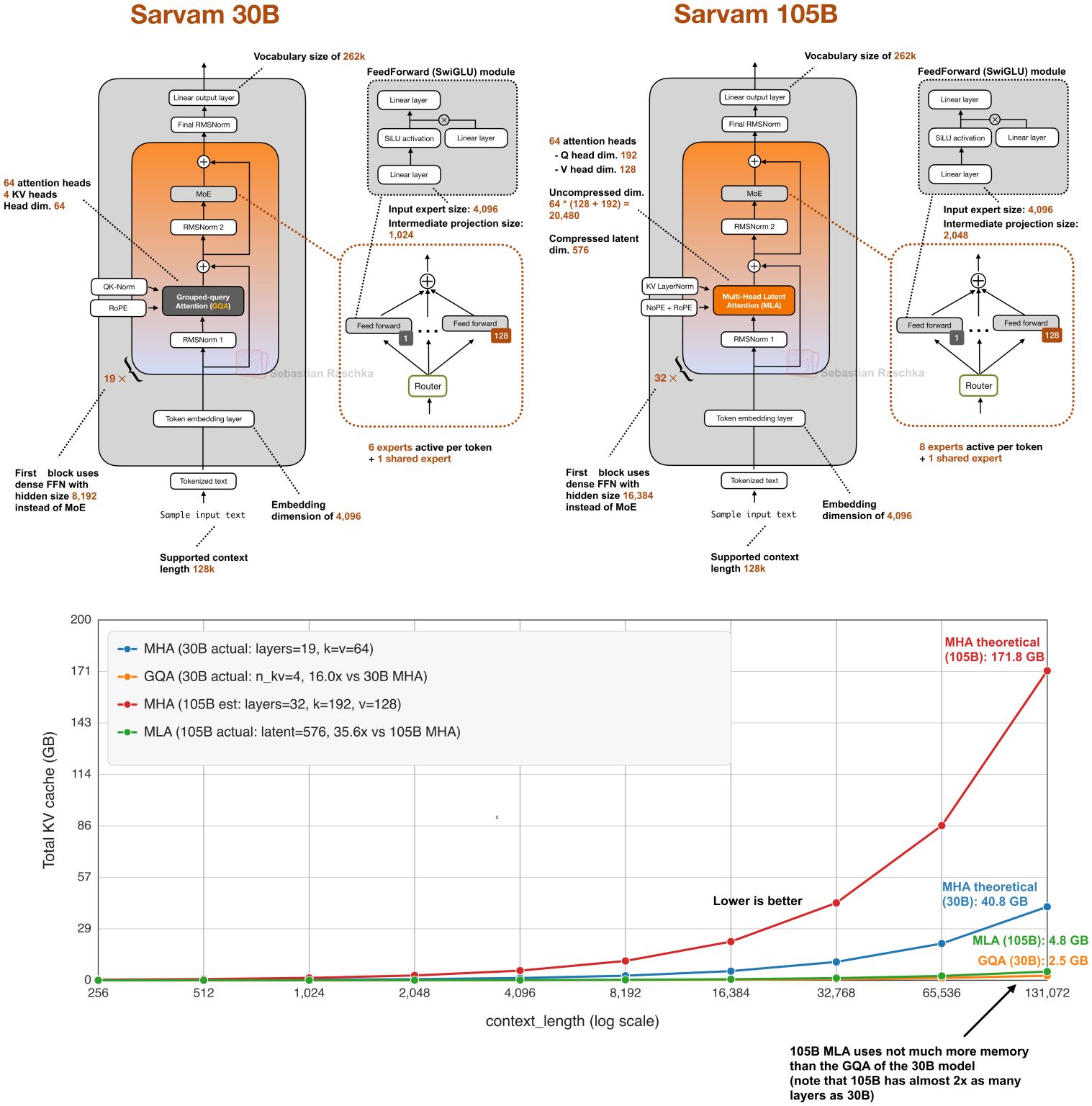
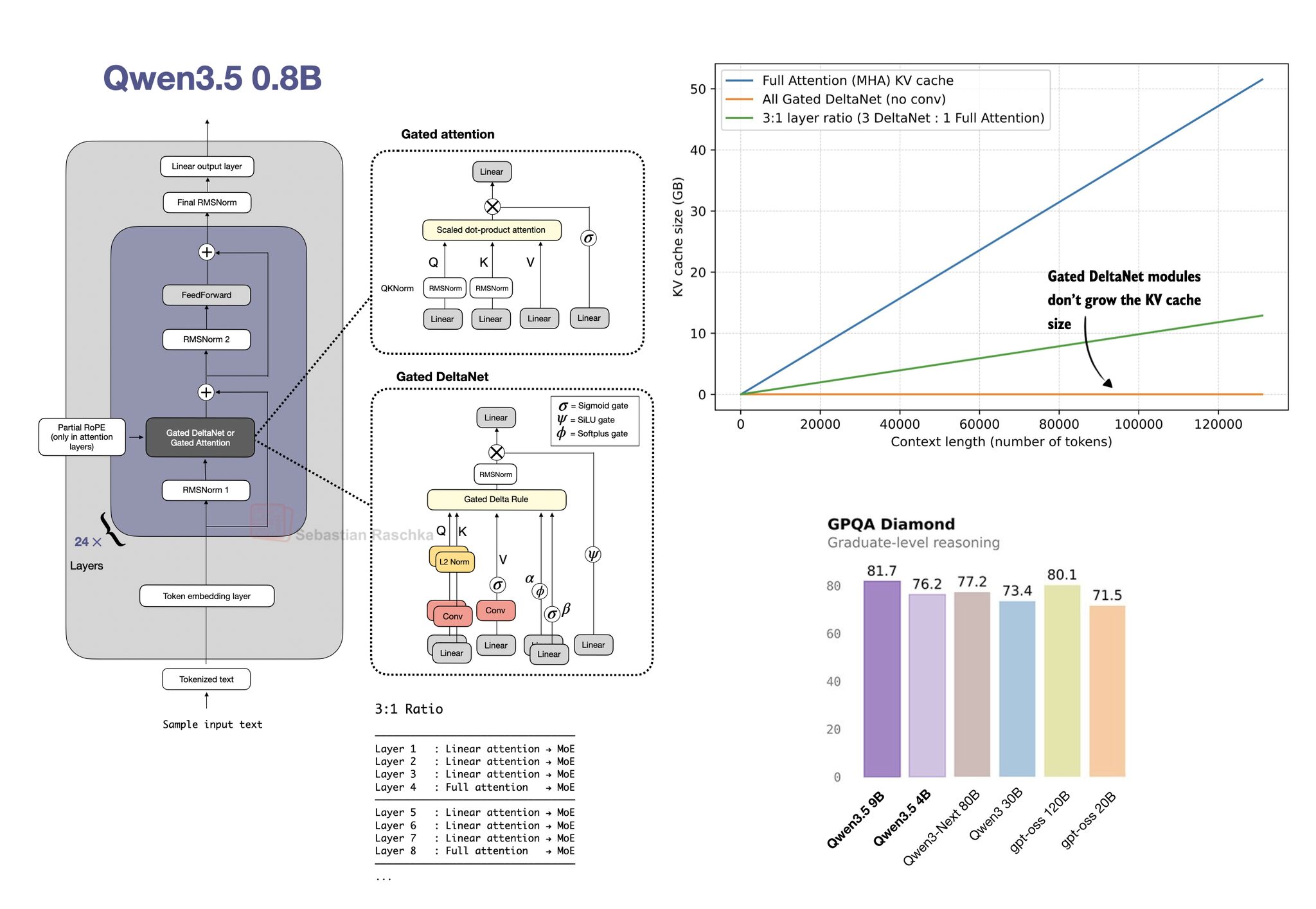
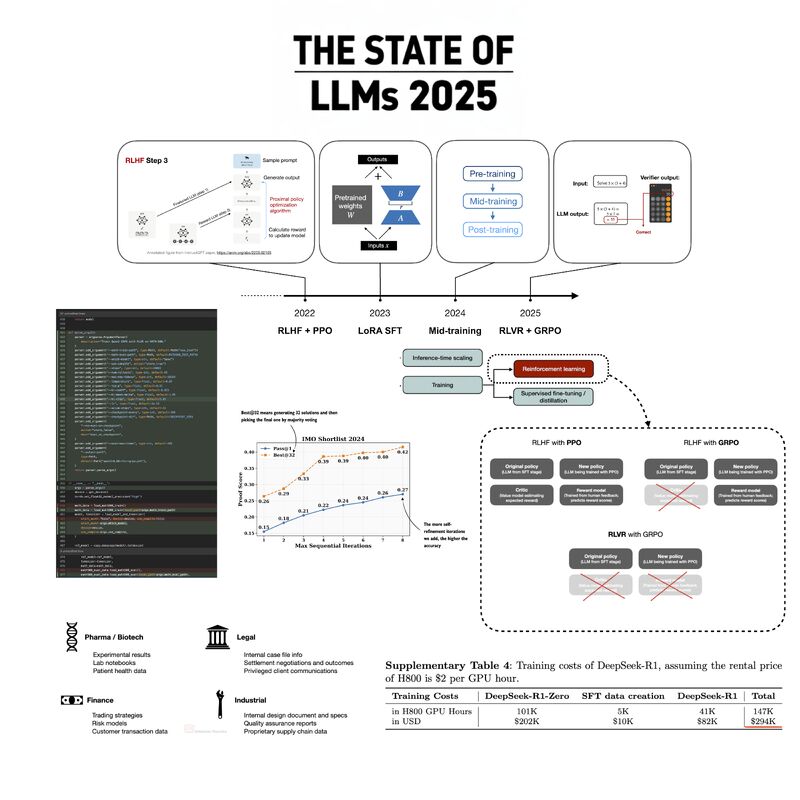
I put together a new LLM Architecture Gallery that collects the architecture figures I shared over the months and years in one place. The goal is to make it easier to quickly browse recent open-weigh…

6.5K18961253 viral
Large Language Models4 months ago