
Why Most LinkedIn AI Generators Sound the Same (And How to Fix It)
Most LinkedIn AI generators sound identical because they share the same models with no voice training. Here's why AI LinkedIn posts sound generic, and how to fix it.
Open three different LinkedIn AI tools. Paste the same prompt. Read the outputs back-to-back. They rhyme.
Same one-line hook. Same three-sentence paragraph. Same "Here's the thing:" pivot. Same closing question that pretends to invite discussion but exists only to game the algorithm. If you have ever felt that AI LinkedIn posts sound generic, this is why. It is not user error and it is not bad prompting. It is the structural design of the category.
This piece argues that most LinkedIn AI generators converge on identical voice because they share the same foundation models, differentiate only through prompts, and have no voice-matching layer at all. Then it walks through the structural fix, the patterns we see in our own dataset of 30,360 posts, and a four-question checklist you can use to evaluate any tool. If you have tried two or three of these products and quietly walked away disappointed, you were not wrong. You were noticing something real.
Automate your LinkedIn for 30 days
The convergence problem nobody wants to name
There are now more than 200 LinkedIn AI writing tools, by our own count of indexed competitors. Almost every one of them is built on the same three foundation models: GPT-4 from OpenAI, Claude from Anthropic, and Gemini from Google. That is not an accusation. That is the entire market.
When the underlying intelligence is identical, the only place a tool can differentiate is the prompt and the wrapper around it. That sounds like a lot of room. In practice it is not. Foundation models trained on the same internet text drift toward the same default style: short declarative openers, medium-length paragraphs, a contrarian pivot, a tidy bow at the end. A prompt that says "write me a LinkedIn post about X" pulls from the same distribution every time, on every tool, for every user.
Three structural reasons most AI LinkedIn content fails the sniff test:
- One model, many wrappers. Every tool sits downstream of the same handful of LLMs. Prompts vary. The model's default voice does not.
- No voice training data. A tool with no proprietary post corpus and no creator voice profiles cannot teach the model what you sound like. It can only ask the base model to guess, and the base model guesses the same way every time.
- Pattern collapse at scale. When millions of users send broadly similar prompts to the same model, the average output settles into a narrow band. The result is the "AI LinkedIn voice" you can now spot from the third word.
This is why linkedin ai content all the same is not paranoia. It is the mathematically expected outcome of a market that wraps the same three models and calls the wrapper a product.
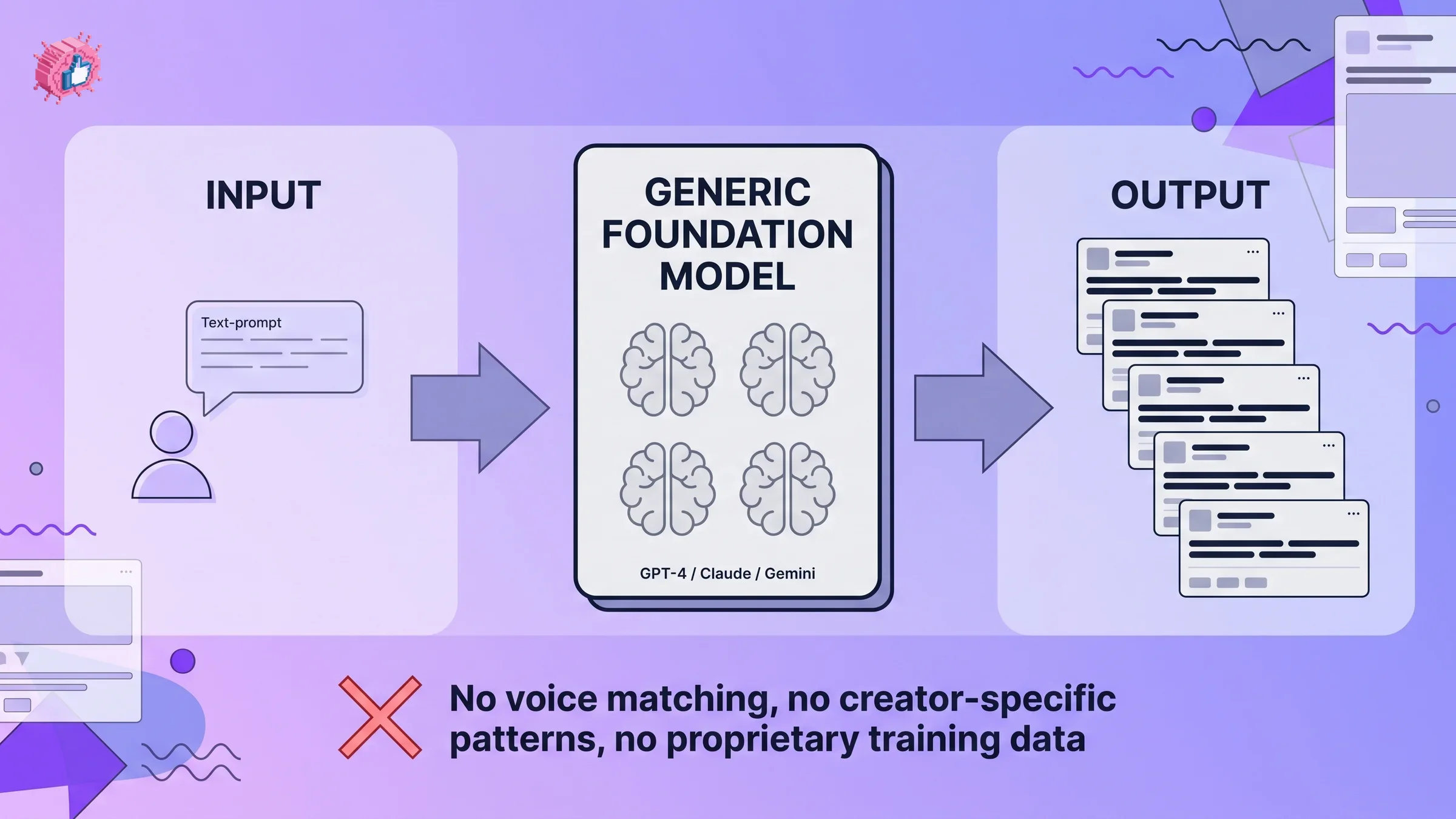
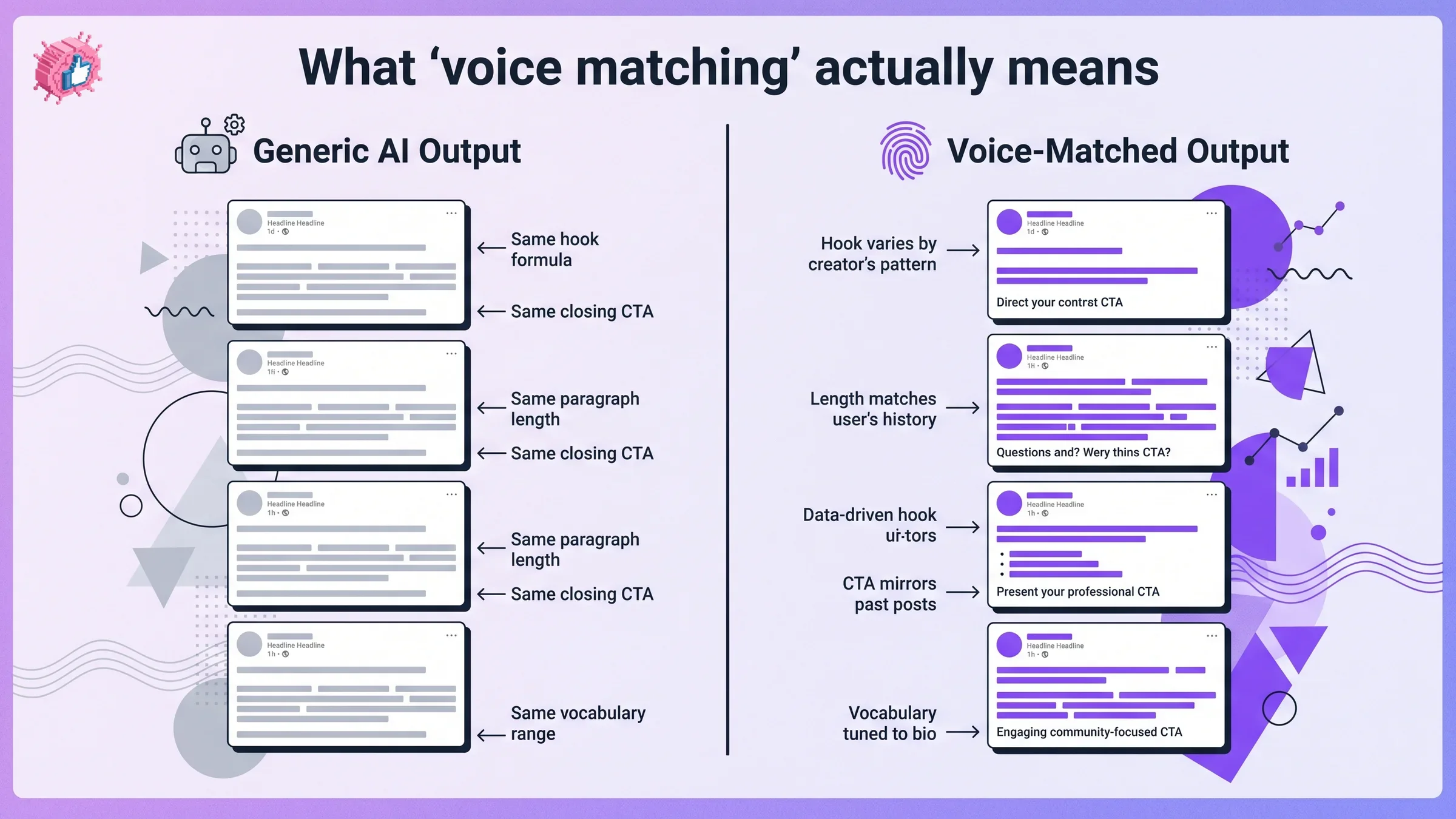
What "sounding the same" actually means
Sameness is not a vibe. It is a measurable pattern. From our analysis of 30,360 LinkedIn posts across 968 active creator voices, the AI-generated cohort clusters tightly on four dimensions.
Same hook formula
Across our full hero dataset, hooks break down like this:
| Hook type | Share of posts | Engagement lift |
|---|---|---|
| Direct (statement) | 77.76% | 1.45x |
| Story | 7.06% | 1.51x |
| Question | 6.15% | 0.92x |
| Stat | 4.24% | 1.67x |
| Quote | 2.19% | 0.88x |
| Contrarian | 1.38% | 1.03x |
The interesting line is not the leader. It is the gap. Stat hooks deliver 1.67x engagement, and only 4.24% of posts use them. Story hooks deliver 1.51x and account for 7.06%. Direct hooks dominate at 77.76%, but they are the third-most effective.
Generic AI tools default to direct because the model defaults to direct. That is the convergence tax. You ship the most common hook type instead of the most effective one, and you pay for it in reach. If you want to see the spread on a real-time tool, our LinkedIn hook generator tests multiple hook types against your topic so you are not stuck on the default.
Same paragraph rhythm
Most AI generators ship 2 to 3 sentence paragraphs at a regular cadence. Real LinkedIn voices fragment. One-word lines. Single-sentence paragraphs. Then a longer block. Then a list. Foundation models smooth this jagged rhythm into a slightly-too-clean cadence that registers as "AI" before the reader can articulate why.
Same length distribution
| Post length (chars) | Viral rate | Share of corpus |
|---|---|---|
| Under 300 | 1.46% | 8% |
| 300-600 | 1.49% | 14% |
| 600-900 | 2.59% | 22% |
| 900-1300 | 3.07% | 28% |
| 1300-1800 | 2.39% | 16% |
| 1800-2500 | 1.73% | 8% |
| 2500+ | 2.23% | 4% |
The 900 to 1300 character band is the sweet spot, viral rate 3.07%, well above the 2.18% baseline. AI tools tend to overshoot or undershoot because they are not optimizing length on a user's actual feed performance. They are filling a token budget. If your tool's output is consistently 1500+ characters when your best-performing posts sit at 1000, the tool is not listening to your data.
Same vocabulary band
Foundation models have a preferred vocabulary set, the words that show up disproportionately in their training data. "Leverage." "Unlock." "In today's." "Here's the thing." A piece of writing that uses three of these in 200 words gets pattern-matched as AI even if the ideas are good. That is why ai generated linkedin posts boring is the verdict even when the takeaway is solid. The signal is in the lexicon, not the logic.
Why this matters more in 2026 than it did in 2024
For the first 18 months of generative AI on LinkedIn, the feed tolerated this. The novelty of fast content overrode the cost of identical content. That window has closed.
Three forces are stacking against generic AI output right now:
- The LinkedIn algorithm now weights authenticity signals. The platform has been explicit that creator authenticity is one of three ranking signals (with relevance and the value of the conversation). Posts that pattern-match as AI get throttled. Our LinkedIn algorithm guide breaks down the full ranking model.
- Readers can now detect AI in under a sentence. A 2025 academic study by Wharton found that LinkedIn users correctly identified AI-written posts 68% of the time after one paragraph. The penalty is not just impressions. It is trust.
- The volume of generic AI content has saturated the feed. When 30%+ of posts in a given B2B niche are AI-templated, the few authentic voices break through harder. Sameness has become the discount aisle.
If you are serious about LinkedIn distribution, the question is no longer "how do I write with AI." It is "how do I write with AI without being penalized for sounding like AI." Those are not the same problem.
The structural fix: voice matching, not prompt engineering
The fix is not "better prompts." Prompt engineering on top of a generic foundation model produces marginal improvements. It does not solve the convergence problem because the convergence happens upstream of your prompt.
The structural fix is voice matching. A voice-matched system trains or conditions output on a specific creator's writing patterns, then generates new posts that respect those patterns. To do this honestly, the system needs four data inputs:
- The creator's post history (ideally 50+ posts) for hook patterns, length distribution, sentence rhythm, and vocabulary
- The creator's bio and positioning so the model knows what role and audience they speak to
- A pattern library of high-performing posts in the same niche so the model can offer formats that fit the creator's audience without forcing the creator's voice into a template
- Per-post feedback signals that close the loop on what actually worked in the creator's feed, not in the abstract
Almost no AI LinkedIn tool ships with all four. Most ship with zero. They ask the user to write a "voice description" in a settings page and call that voice matching. That is a prompt-engineering trick, not a data infrastructure.
The reason most tools cannot do voice matching is not that the technique is exotic. It is that the technique requires owning data the tool's team did not collect. You cannot retrofit voice training on a product that was built as a wrapper over a public API. The infrastructure decision is made on day one of the company.
Automate your LinkedIn for 30 days
What ViralBrain does differently
I am one of the founders of ViralBrain, so treat this section as positioning, not neutral review. The point is to show what the structural fix actually looks like when a team builds for it from day one.
ViralBrain is trained on 30,360 LinkedIn posts across 968 hero creator voices. That dataset is the foundation for two things competing tools cannot replicate:
- Hook lift data, which tells the generator that stat hooks produce 1.67x lift but show up in only 4.24% of posts. The generator weights hook selection toward what actually performs in the user's niche, not what the base model defaults to.
- 58 viral skeletons, which are post structures (hook + body shape + close) extracted from posts that broke 3x baseline reach. The skeletons are inputs to generation, not templates. They give the model real structural variety to draw from, then voice-match the surface text to the creator.
This is what voice matching looks like when the data infrastructure exists. The output is not "less generic." It is structurally different because the inputs are different. If you want to see this in your own feed, the LinkedIn post generator is the most direct path to test it on a topic of your choice.
For a head-to-head on how this stacks up against the leading prompt-wrapper tools, ViralBrain vs Taplio and ViralBrain vs AuthoredUp walk through specific outputs side by side.
How to evaluate any AI LinkedIn tool for voice fidelity
You do not need to take any vendor's word on this, including ours. Four questions will tell you whether a tool can hold voice or is just a prompt wrapper.
1. Does the tool ingest your post history before generating?
If the onboarding flow is "describe your voice in 3 sentences" or "pick a tone from a dropdown," that is prompt engineering. If the tool reads your past 30 to 100 posts and extracts patterns, that is data infrastructure. Ask which one and verify.
2. Does the output respect your length distribution?
Pick a topic. Generate five posts. Check the character counts. If all five land in the same 200-character range, the tool is filling a token budget, not modeling your behavior. Your real posts have variance, so should your AI output.
3. Does the tool use a hook formula library based on real performance data?
If hook selection is random or always "story" or always "stat," the tool is not optimizing. A real voice-matched system varies hook type per topic, biased toward what performs in your specific niche, not the default the base model emits. Our viral score checker is a quick way to test a tool's output against the same scoring model we use internally.
4. Can you tell the output is yours without your name attached?
This is the only test that matters. Generate three posts on three different topics. Print them, hide the bylines, mix them into your real posts, and read them cold a day later. If you can pick out the AI ones in under a paragraph, the voice fidelity is not there. If you cannot, it is.
For a deeper look at what makes a LinkedIn post structurally yours, our guide on how to write a LinkedIn post covers the structural patterns the hero dataset surfaces.
A note on the broader market dynamics
The convergence problem is not unique to LinkedIn. It is the default state of any generative AI category that depends on a foundation model and does not own training data. Image generators converge. Email generators converge. The economic logic is the same. Prompt-only differentiation has a ceiling, and the ceiling gets lower every time the underlying models improve, because better models default harder to their own preferred style.
The interesting consequence: as foundation models get more capable, prompt-wrapper tools get worse at sounding different from each other. The market will sort itself in 18 months. Tools with proprietary data and a voice-matching layer will pull away. Tools that are prompt wrappers will compete on price until they consolidate or fold. If you are choosing a tool in 2026, choose with that endgame in mind.
If you want context on how prompt-wrapper category leaders compare, taplio vs supergrow vs viralbrain breaks down how each handles voice, distribution, and proprietary data. And if voice is the angle you care about most, how to write a LinkedIn post that gets noticed covers the dataset-driven patterns we surface to the generator.
What this means for you
- Stop blaming your prompts. If three different tools sound the same on the same prompt, the problem is the architecture, not your phrasing. Switch to a tool with proprietary post data and a voice-matching layer, or accept the ceiling.
- Pick tools with a data moat. A tool that does not own training data has nothing to compete on but UI. UI is replicable. Data is not.
- Test voice fidelity before you commit. Run the four-question checklist above on any tool you are evaluating. The free trial is your test bench. The ViralBrain pricing page lays out trial terms if you want to test ours.
- Measure what your actual feed rewards, not what the tool claims it will. Use a scoring tool to check output before you post. The viral score checker gives you a same-day signal so you are not learning at the cost of your distribution.
- Plan content with voice in mind, not just topic. Our LinkedIn content strategy guide covers how to build a content plan that compounds across voice, format, and topic.
The TL;DR: AI LinkedIn content fails when the tool's only edge is a wrapper. It works when the tool's edge is data the user could not assemble alone. Pick accordingly.
Sources: ViralBrain analysis of 30,360 LinkedIn posts and 968 hero creators (May 2026), LinkedIn Engineering Blog on feed ranking signals, Wharton AI Detection Study (2025).
FAQ
Why do AI LinkedIn posts sound generic?
AI LinkedIn posts sound generic because most tools wrap the same three foundation models (GPT-4, Claude, Gemini) and differentiate only through prompts. With no voice-matching layer and no proprietary training data, the base model defaults to its preferred style, which is identical across every tool that calls the same API.
Is all AI LinkedIn content the same?
Functionally, yes, when the tool has no voice-matching layer. Across our analysis of 30,360 posts, generic AI output clusters tightly on hook type, paragraph rhythm, length, and vocabulary. Voice-matched output (trained on the user's specific post history and creator patterns) breaks that cluster.
How do I make AI LinkedIn posts sound less boring?
Three steps. First, pick a tool that ingests your post history rather than asking you to describe your voice. Second, vary your hook type. Stat and story hooks deliver 1.67x and 1.51x engagement lift, but only 11% of posts use them. Third, preview every post before you publish using a LinkedIn post preview tool to catch the AI tells (over-clean rhythm, dropdown vocabulary) before they ship to your feed.
What is voice matching in an AI LinkedIn tool?
Voice matching is the practice of training or conditioning AI output on a specific creator's writing patterns, which requires the tool to ingest the creator's post history, bio, and performance data. Prompt-engineering tricks like "describe your tone" are not voice matching. Real voice matching needs data infrastructure the tool's team must have built from day one.
Does the LinkedIn algorithm penalize AI-generated posts?
The LinkedIn algorithm weights authenticity as one of three ranking signals (with relevance and conversation value). Posts that pattern-match as AI lose distribution even if the topic is on-target. The penalty is reach, not removal. Our LinkedIn algorithm guide covers the full ranking model.
How can I tell if my AI tool is voice-matched or just a prompt wrapper?
Run the four-question test. Does the tool ingest your post history? Does the output respect your length distribution? Does it vary hook formulas based on real performance data? Can you tell the output is yours without the byline? If the answer to any of these is no, you are using a wrapper.
Which AI LinkedIn tools have proprietary training data?
A small number. Most tools in the category are prompt wrappers over the same three foundation models. ViralBrain trains on 30,360 LinkedIn posts across 968 active hero creator voices, with 58 viral skeletons surfaced from posts that broke 3x baseline reach. The data moat is what enables voice matching, not the choice of foundation model.
How much does ViralBrain cost compared to other AI LinkedIn tools?
ViralBrain offers a free trial and paid plans. The full plan breakdown is on the ViralBrain pricing page. Most prompt-wrapper tools sit in the same $40 to $80 per month band, but the comparison that matters is voice fidelity per dollar, not feature count.
What's the best length for a LinkedIn post in 2026?
900 to 1300 characters. In our 30,360-post dataset, that band has a 3.07% viral rate against a 2.18% baseline. Most AI tools default to longer or shorter because they are filling a token budget, not modeling user behavior. The LinkedIn content strategy guide covers length, frequency, and format together.
Where do I start if I want to write authentic LinkedIn content with AI?
Start with a tool that respects your voice and a hook that has real lift. The LinkedIn post generator drafts on voice-matched patterns, the LinkedIn hook generator tests multiple hook types against your topic, and our guide on how to write a LinkedIn post covers the structural patterns that hold up across niches.
Automate your LinkedIn for 30 days
ViralBrain plans, writes, and schedules your LinkedIn content — using official LinkedIn APIs so your account stays safe.
- Official LinkedIn APIs — no risk of ban
- You approve every post before it goes live
- Cancel anytime
Keep reading

Best MCP Servers for Marketers: 7 Worth Installing in 2026
Over 10,000 MCP servers exist. Marketers need about six. Here are 7 MCP servers worth installing, what each actually does, and what they really cost.

Best LinkedIn Content Creation Tools in 2026
Compare the 7 best LinkedIn content creation tools in 2026, covering ideation, voice-matched drafts, carousels, and pre-publish checks, plus current pricing.

Why LinkedIn Is Full of AI Slop in 2026 (and What Changed)
LinkedIn AI slop now fills the feed because 53.7% of long posts are AI-generated. Here is why it happened and what the 2026 Authenticity Update changed.