💥 I did a drawing that breaks down Transformers in AI Spent a good amount of time on this one, breaking down concepts in a way that someone new to the subject could come away with basic high-level u…
443293293 viral
AI Education6 months ago

LinkedIn Content Strategy & Writing Style
Sr Director of Engineering at Google: Web, Android, iOS, o11y, Experimentation and Multiplatform Core Infrastructure
0 people tracking this creator on ViralBrain
Sarah Drasner positions herself as a high-level engineering leader who retains the soul of a practitioner, bridging the gap between complex infrastructure and accessible education. Her content strategy centers on visual technical storytelling, where she uses hand-drawn "code drawings" to demystify intricate topics like WASM, GPU architecture, and AI Transformers. What makes her notable is the rare intersection of executive-level oversight at Google and a hands-on commitment to creative pedagogy, proving that deep technical expertise can be both rigorous and aesthetically engaging. By blending personal reflections on leadership with these visual explainers, she offers a unique value proposition where multiplatform engineering meets high-fidelity knowledge design.
8.8K
2.3K
175
—
0.8
215
1
💥 I did a drawing that breaks down Transformers in AI Spent a good amount of time on this one, breaking down concepts in a way that someone new to the subject could come away with basic high-level u…
✍️ Over break I finally added my code drawings to my site! I have series on Android, WASM, Rendering on each platform, and the beginning of JS Fundamentals. Enjoy! https://sarah.dev/projects
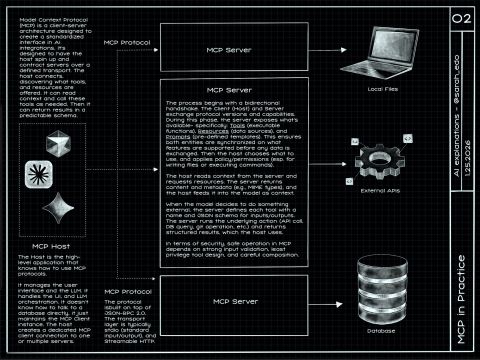
✍️ Just finished another code drawing in my AI series, this one's about MCP in practice. Enjoy!
🎊 Just wrapped up my 2025 reflections, and well, it was a wild year. I reflected on how the AI shift has changed my role at Google, and the way teams build. At the same time, I worked on keeping ba…
💥 Next up in visual explainers: the difference between GPU and CPU! This may be review for some but good to cover- For instance, understanding when you would make good use of GPU and layer promotio…

💥 Last visual explainer for the week! The WASM compilation workflow, with a little zoom in to the details of C/C++ We've been leveraging WASM for deep performance, portability, and at times security…
0.8 posts/week
Posts / Week
10.7 days
Days Between Posts
1
Total Posts Analyzed
LOW
Posting Frequency
175%
Avg Engagement Rate
STABLE
Performance Trend
85
Avg Length (Words)
HIGH
Depth Level
ADVANCED
Expertise Level
0.86/10
Uniqueness Score
YES
Question Usage
0.3%
Response Rate
Writing style breakdown
<start of post>
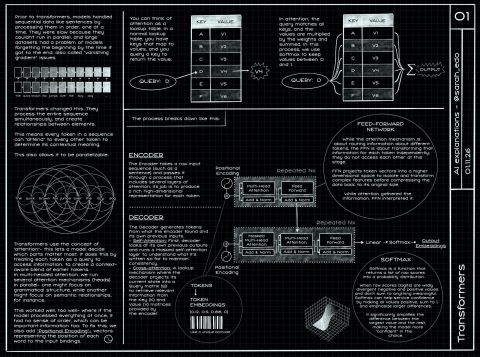
💥 Just finished a new code drawing in my AI series, this one’s about how Transformers actually move information around in practice. Enjoy!
I spent a good amount of time on this one because it’s easy to memorize the words (attention, embeddings, heads) without ever getting a feel for what’s happening at each step. My goal was that someone new to the subject could come away with basic high-level understanding, but also that an experienced engineer could point at a box in the diagram and say ‘yep, that part matters’.
If you’ve only ever seen the “attention is all you need” headline version, the first surprise is that most of the work is just clean bookkeeping: taking tokens, turning them into vectors, and then doing the same few operations repeatedly, layer after layer, with slightly different learned weights.
One thing I wanted to make visually obvious is what changes across layers and what doesn’t. The tokens don’t magically become “meaning”, they become a set of numbers that are useful for predicting the next token, and the model keeps remixing those numbers through the same pattern of projections, dot products, and mixes.
The attention step is the star, but it’s also the easiest part to misunderstand if you never slow it down. You’re not “searching the internet” inside the model. You’re computing similarity between one vector and other vectors in the same context window, turning that into weights, and then using those weights to blend information forward. That’s it. Still incredibly powerful, but not mystical.
multi-head attention isn’t just “more attention”, it’s parallel subspaces that each get to specialize
masking is a constraint that shapes what can influence what, and it’s foundational for next-token prediction
the feed-forward block looks boring on paper, but it’s a huge chunk of the compute and capacity
Also, I tried to highlight where shapes matter (sequence length vs hidden size) because a lot of confusion comes from not knowing what dimension you’re multiplying by what. Once you can track the shapes, the whole thing becomes less intimidating, and you can start asking better questions about performance and memory.
If you’re coming from mobile or web performance work, this ends up feeling familiar: you’re moving and transforming big buffers of numbers, and the system is fast when you keep things batched, predictable, and hardware-friendly. That’s part of why GPU vs CPU intuition is useful here, even if you never write CUDA.
I’ve also been thinking a lot about the “practical” side lately: what you do when you want to apply this to a product. The model architecture is one piece, but the surrounding workflow (data, evaluation, guardrails, latency budgets) is where most real teams spend their time. It’s similar to WASM in that way: the tech is exciting, but the leverage shows up when it fits into a real pipeline and stays maintainable.
If you read this and think “ok, but when would I ever need to know this level of detail?”, you probably don’t for day-to-day API usage. But it’s extremely helpful when you’re debugging odd outputs, trying to understand why a model is slow, or evaluating tradeoffs between context length, model size, and quality.
I’d love to hear what’s been most confusing (or most surprising) as you’ve learned this stuff.
https://sarah.dev/projects
<end of post>
Sign in to unlock the full writing analysis
Free tools to help you write, score, and benchmark in the same style.
Other creators worth studying alongside Sarah Drasner.

Harry Cook
Ex-carpenter turned tech recruiter | Building high-performance engineering teams in Berlin! 💻
87 Viral Score

John Curmi
Norway Tech Consultant
96 Viral Score

Stanislav Tanev
HR | Recruitment | Org Development @Endurosat
4 Viral Score

Andy Wong
Engineering @ Meta | prev. @Block, Google, Amazon | Advocate for underrepresented groups and non-traditional backgrounds in tech
33 Viral Score

Ricardo Viana Vargas, Ph.D.
Global Leader in Project Management | Pioneer in AI Applied to Projects | Founder of PMOtto.ai and Macrosolutions | Board Member (IBGC - CCA) | IPMA-A | PMI Past Chairman | PMI Fellow | Author | Venture Capitalist
15 Viral Score

Pierre Le Manh
President and CEO, PMI
45 Viral Score
ViralBrain plans, writes, and schedules your LinkedIn content — using official LinkedIn APIs so your account stays safe.
Write like Sarah Drasner.