
How to Write a LinkedIn Post That Gets Noticed in 2026
Learn how to write a LinkedIn post that gets noticed in 2026, backed by data from 30,360 posts. Hook formulas, length sweet spot, and CTA patterns that work.
Most advice on how to write a post on LinkedIn is built on what creators think works, not what actually does.
We pulled the receipts. After analyzing 30,360 LinkedIn posts from 968 active hero creators (snapshot May 2026), one number stands out: 77.76% of posts open with a "direct" hook, but direct hooks are only the third strongest performer. Stat hooks deliver 1.67x more engagement than baseline. Imperative hooks (the "Read this", "Stop doing this" openers) deliver 0.02x. They are functionally dead.
This article walks you through how to write a LinkedIn post that gets noticed in 2026, using engagement data from real posts. You will get five hook formulas with measured lift, a length sweet spot down to the character, a CTA pattern that earns 15x more algorithmic weight than likes, and a line-by-line breakdown of an 11,576-like viral post.
Automate your LinkedIn for 30 days
What "noticed" actually means in 2026
Before we talk craft, let's define the target. "Noticed" on LinkedIn in 2026 is a measurable engagement rate that signals to the algorithm your post is worth distributing.
According to SocialInsider's Q1 2026 benchmark report, the average personal-profile engagement rate is 3.85%, up roughly 44% year-over-year. Company pages sit at 2.1%. The thresholds people use:
- Average performance: 1 to 2% engagement rate
- Good performance: 4 to 6%
- Excellent: 6 to 10%
- Exceptional (top 4% of posts): 10%+
In our dataset, the baseline viral rate (posts hitting outsized reach relative to follower count) is 2.18%. The job of the structure below is to push you from baseline toward the 3.07% sweet spot and, on your best days, into the top tier.
For the mechanics of how reach is calculated, the LinkedIn algorithm guide covers it. The short version: comments outweigh likes by a factor of 15, dwell time matters more than ever, and the post has 3 to 8 hours to prove it deserves wider distribution.
The hook decides everything (within 2 seconds)
LinkedIn users make a continue-or-scroll decision in roughly 2 seconds. Every research source on hook performance, from UseVisuals' framework studies to Kleo's library of 203 hook templates, lands on the same finding: the first 1 to 2 lines determine 80%+ of whether your post gets read at all.
Our dataset confirms this with hard numbers. We classified all 30,360 posts by hook archetype and measured engagement lift (multiplier vs the corpus baseline) for each type. The result is the most counterintuitive insight in the report.
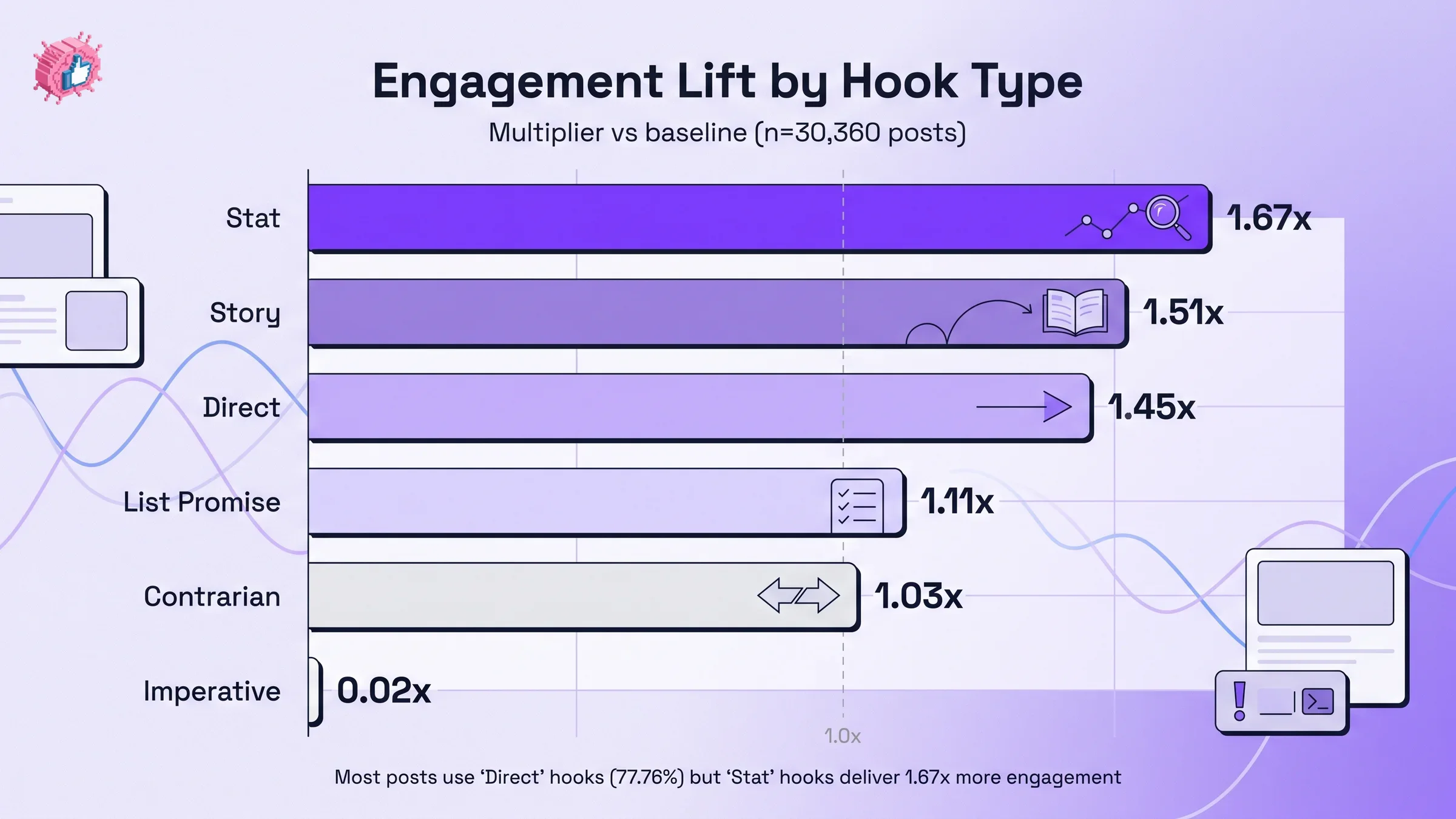
| Hook type | % of posts using it | Engagement lift (multiplier) |
|---|---|---|
| Direct | 77.76% | 1.45x |
| Story | 7.06% | 1.51x |
| Question | 6.15% | (not significant) |
| Stat | 4.24% | 1.67x |
| Quote | 2.19% | (not significant) |
| Contrarian | 1.38% | 1.03x |
| Imperative | 1.02% | 0.02x |
| List promise | 0.20% | 1.11x |
Three things stand out:
- Stat hooks (4.24% of posts) outperform direct hooks (77.76%) by 15%. Most of the supply is in the wrong format.
- Imperative hooks are dead. "Stop doing X." "Try this today." 0.02x lift means they actively suppress reach. The algorithm has learned the pattern and the audience has tuned it out.
- Story hooks underperform stat hooks by only 9%, but compound much harder when paired with the right body structure (more on this below).
The implication: if you are writing a "direct" hook, you are competing in the most crowded category for marginally lower lift. If you have a number, lead with the number. If you have a moment, lead with the moment.
You can pressure-test any hook against this dataset using the LinkedIn hook generator, which surfaces variations sorted by archetype.
The 5 hook formulas that actually win
Across the 653 viral posts in our corpus, five repeating skeletons explain most of the outsized performance. Each one matches a hook archetype above and pairs it with a specific body shape.
1. The Stat Hook (1.67x lift)
When to use it: launches, milestones, results, surprising data points.
Pattern: lead with a single, specific, large-magnitude number. Then immediately answer "why does this matter to the reader."
Skeleton it powers: "Credibility Cheat Sheet" (2.88x lift). The post leads with a number that establishes the writer's authority, then unpacks 3 to 5 specific decisions or insights that produced it.
Example opening:
Lovable just raised $330M at a $6.6B valuation.
That is the actual opening line of Anton Osika's announcement, which generated 11,576 likes and 562 comments. We will walk through the full structure of that post below.
2. The Story Hook (1.51x lift)
When to use it: identity moments, transitions, lessons learned, "before and after" reflections.
Pattern: drop the reader into a specific scene with a concrete subject and a tension. No set-up. The micro-story is already in motion.
Skeletons it powers:
- "Identity Pivot Narrative" (3.48x lift): "I used to be X. Now I am Y. Here is what changed."
- "Full-Circle Reflection" (3.30x lift): retrospective looking back on a decision, with the punchline arriving at the end.
Example opening:
Three years ago I was 90 days away from running out of cash. Today we crossed $5M ARR. Here is what I would do differently.
3. The Direct/Utility Hook (1.45x lift)
When to use it: tactical posts, deep-dive guides, frameworks, breakdowns.
Pattern: state the value the reader will get if they keep scrolling, in plain language, with a specific number or named framework.
Skeleton it powers: "Feature Deep-Dive Guide" (4.58x lift, the highest in our entire skeleton dataset). A direct opener followed by a structured walkthrough of a tool, tactic, or workflow.
Example opening:
The 7-step LinkedIn cold message I used to book 42 sales calls last quarter.
The lift on this skeleton is 4.58x because the structured payoff (a numbered, scannable body) keeps dwell time extremely high.
4. The Contrarian Hook (1.03x baseline lift, but 3.29x on the right skeleton)
When to use it: pattern interrupts, takedowns of consensus advice, unpopular opinions backed by data.
Pattern: flip the conventional wisdom in the opening line, then prove it.
Skeleton it powers: "Punny Power-Up" (3.29x lift). The post opens with a contrarian claim wrapped in a wordplay or hook that subverts expectations, then delivers a substantive argument.
Example opening:
Posting daily on LinkedIn killed my engagement. Here is the data.
The base "contrarian" hook archetype is only 1.03x at corpus level because most contrarian openings are weak. But when paired with concrete proof and a wordplay framing, lift jumps to 3.29x.
5. The Question Hook (use sparingly)
The data on question hooks is mixed. They appear in 6.15% of posts but show no significant lift over baseline at the corpus level. Two patterns do work:
- A specific, niche question that screens for the right audience ("If you run a 50-person remote team, how do you handle async standups?")
- A question that primes a counterintuitive answer in the body
Generic questions ("What's your favorite productivity hack?") are dead weight.
What to avoid: imperative hooks
The 0.02x engagement lift on imperative hooks is the single largest negative finding in our dataset. Lines like "Stop overthinking", "Read this if you are a founder", "Do this every morning" pattern-match to the lowest-quality content on LinkedIn. The algorithm has learned the pattern, and so have readers. Cut every imperative opener from your drafts.
If you want a curated library of openers organized by archetype and lift, the viral post templates library has 200+ tested variations.
The body: length, format, and dwell-time signals
Once the hook earns the click-through to "see more", the body has one job: keep the reader on your post long enough to register dwell time. Dwell time is now one of the three core ranking signals (alongside engagement velocity and authenticity), per the 2026 algorithm analysis from Sourcegeek and Dataslayer.
The dataset is unambiguous about where the dwell-time sweet spot sits.
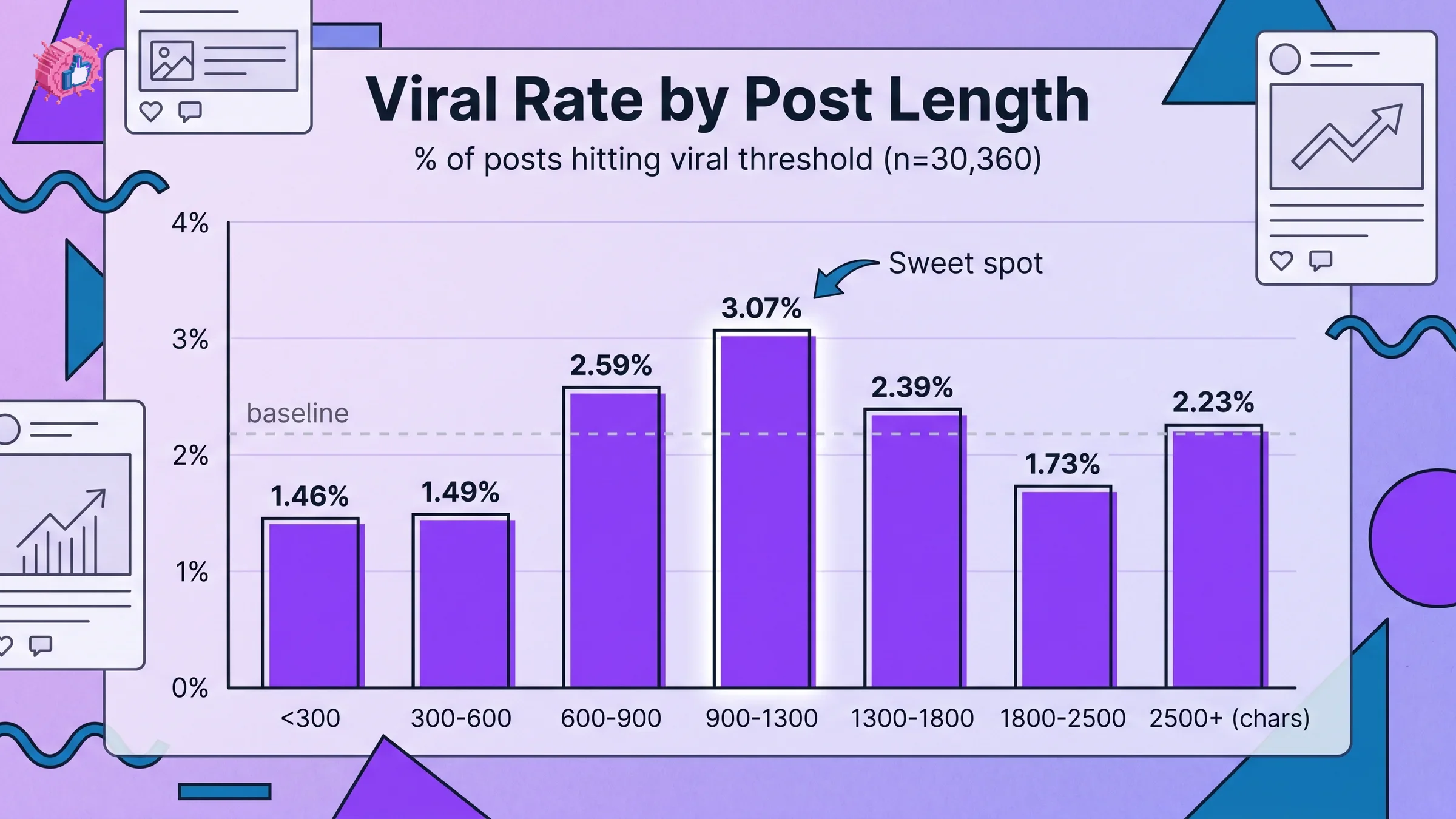
| Character range | Viral rate (% of posts) |
|---|---|
| Under 300 chars | 1.46% |
| 300 to 600 | 1.49% |
| 600 to 900 | 2.59% |
| 900 to 1,300 | 3.07% (sweet spot) |
| 1,300 to 1,800 | 2.39% |
| 1,800 to 2,500 | 1.73% |
| 2,500+ | 2.23% |
Three things to notice:
- The 900 to 1,300 character range is 2.1x more likely to go viral than sub-300 character posts. "Brief and punchy" is a myth at the data level.
- The viral rate drops from 1,300 to 2,500 chars before recovering at 2,500+. This is the "long-form bonus": once you commit to a genuinely long post, dwell time compounds and pushes posts back over the viral threshold.
- Avoid the dead zone at 300 to 600 characters. It is the worst range in the dataset because there is not enough content to register dwell time, but enough text that readers feel obligated to scan rather than react.
Body structure principles
Inside the 900 to 1,300 char range, the highest-lift posts share five body conventions:
- Aggressive line breaks. One idea per line. The "see more" cutoff is the second hook. Force readers to expand by giving them a visually inviting, scannable shape underneath.
- Specific concrete details. Names, numbers, places, dates. Generic abstractions kill dwell time because they offer nothing the reader's brain needs to process.
- Sub-anchors every 3 to 4 lines. Mini-headlines, emoji-free arrows like "→", or numbered steps that act as visual landmarks.
- One thesis per post. Posts that try to make 3 arguments compete with themselves. The "Identity Pivot Narrative" wins (3.48x lift) because it makes one structural claim and supports it.
- A pivot in the last third. Either a twist (story posts) or the synthesis (utility posts). Posts that flatline at the end lose comment velocity.
If you want to format a draft to match the visual conventions above, the LinkedIn post preview tool renders your text exactly as it will appear in the LinkedIn feed, so you can spot weak line breaks before publishing.
Automate your LinkedIn for 30 days
The CTA: comment-bait without sounding desperate
Comments carry 15x the algorithmic weight of likes, per the February 2026 analysis from Dataslayer. That single fact reshapes how you should end a post. The CTA is not an afterthought, it is the second most important line in your draft (after the hook).
The patterns that work in the dataset:
1. The Resource Bribe
Offer a specific, valuable asset in exchange for a comment. The trade has to feel honest.
If you want the full 12-page playbook, comment "playbook" and I will DM it.
This works because it converts passive readers into commenters, and it gives the algorithm exactly the signal it values most.
2. The Specific Question
Ask a question that screens for genuine engagement and triggers expertise sharing. The narrower the question, the higher the comment quality.
What is the smallest team size where you have seen Slack genuinely replace standup meetings?
Not "What do you think?" The specificity is what converts.
3. The Counterpoint Invitation
Stake a claim, then invite disagreement.
I think LinkedIn polls are dead. Convince me otherwise.
This works because it gives readers a clear, low-friction comment template (state your case) and creates the kind of back-and-forth thread that boosts dwell time across the entire post.
What to avoid
- Generic "What do you think?" closers. They are noise and the algorithm has learned to ignore them.
- "Tag someone who needs to read this." The pattern is over-fished.
- Closing with a link out. External links suppress reach in 2026 (Sourcegeek). If you must include a link, drop it as the first comment instead.
For a focused breakdown of viral structures and CTA pairings, see the how to go viral on LinkedIn guide.
Real example walkthrough: Anton Osika's $330M raise post
Theory is one thing. Let's annotate a real viral post line by line. Anton Osika, founder of Lovable, posted his Series B announcement on LinkedIn and earned 11,576 likes, 562 comments, and uncountable shares. The original post is on LinkedIn here.
Here is the structural breakdown.
Hook (Stat archetype, 1.67x lift):
Lovable just raised $330M at a $6.6B valuation.
One sentence. One number. The number is large enough to stop the scroll instantly, and the company name does double duty as authority signal. No throat-clearing, no "I am thrilled to announce." The hook is the news.
Pivot (line 2 to 3):
This is not a finish line. It is a starting line.
Most stat-led announcements fail here. They lead with the number, then list the investors. Anton pivots immediately to a story frame that signals the post is about something larger than the raise, and dwell time goes up.
Body (gratitude-tribute structure, ~2,500 chars):
The body lists the people who made the milestone possible: customers, team, investors, mentors. It uses aggressive line breaks (one name per line), and each tribute carries a specific one-line reason.
This puts the post in the 2,500+ char bucket, which our data shows hits a 2.23% viral rate. The gratitude structure earns the dwell time because each line offers a discrete reason to keep reading.
CTA (Resource Bribe + Counterpoint hybrid):
The closer is a specific, role-defined invitation for the audience's input on what Lovable should build next, not a generic "What do you think?".
Why this post worked: highest-lift hook archetype (stat at 1.67x), long-form bonus zone (2,500+ chars), authentic gratitude structure that earned dwell time, CTA that earned comments (15x like weight). Every choice is doing algorithmic work.
You can run any draft through the viral score checker to estimate performance before publishing.
Common mistakes that kill engagement
Across the 30,360 posts we analyzed, four mistakes account for most underperformance. Each one is a fixable habit, not a talent issue.
Mistake 1: Posts under 300 characters
The data is brutal: sub-300 char posts hit a 1.46% viral rate, less than half the 3.07% sweet spot. Short posts feel "punchy" but they offer no surface area for dwell time. The algorithm reads them as low-effort and distributes accordingly.
Fix: minimum 600 characters. Aim for 900 to 1,300.
Mistake 2: Imperative hooks
"Stop doing this." "Read this if you are a founder." "Do these 3 things every morning." 0.02x engagement lift, in our dataset, across thousands of examples. The algorithm has learned the pattern.
Fix: replace every imperative opener with a stat hook, story hook, or contrarian claim.
Mistake 3: No comment hook in the CTA
Posts that end with "What do you think?" or no CTA at all consistently underperform posts with a Resource Bribe, Specific Question, or Counterpoint Invitation. Since comments carry 15x like weight, this is the single largest unforced error in the corpus.
Fix: every post should end with a structured CTA that gives readers a specific reason to comment.
Mistake 4: Generic openers ("Today I want to share...")
Soft openers ("Today I'd like to talk about", "Recently I have been thinking about") are pattern-matched by readers as low-stakes content and skipped. They occupy the worst possible position: the hook line, but with no hook.
Fix: cut every "Today I", "Recently I", "I want to share" opener. Lead with the substance.
What this means for you
If you take only the top-priority moves from this article, here is your playbook for the next 30 days:
- Lead with a stat hook on at least 1 in 3 posts. Stat hooks deliver 1.67x lift but only 4.24% of posts use them. The supply gap is your opportunity. Pull a number from your work or your data and lead with it.
- Target the 900 to 1,300 character sweet spot for 70% of your posts. This is the highest-viral-rate range in our entire dataset (3.07%). ViralBrain flags drafts outside this range automatically.
- End every post with a structured CTA: Resource Bribe, Specific Question, or Counterpoint Invitation. Comments carry 15x like weight, so this single change can double your reach over a month.
- Cut every imperative opener. "Stop", "Read this", "Try this" pulled 0.02x lift. Replace with stat or story.
- Build a hook bank. Save 20 hook variations across the 5 archetypes and rotate. The LinkedIn post generator generates voice-matched variations against the dataset patterns above.
For a deeper read on the algorithm signals these tactics target, see the companion piece on the LinkedIn algorithm in 2026. Pricing for ViralBrain (free trial available, plus 100+ free tools at /tools/*) is on the pricing page.
Sources: SocialInsider Q1 2026 LinkedIn Benchmarks, Sourcegeek: How the LinkedIn Algorithm Works (2026 Update), GrowLeads: LinkedIn Algorithm 2026, Text vs Video Reach, Dataslayer: LinkedIn Algorithm February 2026, UseVisuals: Top Frameworks for Viral LinkedIn Hooks, Kleo: 203 LinkedIn Hook Templates, ViralBrain analysis of 30,360 LinkedIn posts from 968 active hero creators (snapshot May 2026).
FAQ
How long should a LinkedIn post be in 2026?
The data sweet spot is 900 to 1,300 characters, which carries a 3.07% viral rate against a 2.18% baseline. Long-form posts (2,500+ chars) also perform well at 2.23%, but the 300 to 600 range is the dead zone. If you are publishing more than once a week, default to the 900 to 1,300 sweet spot and use the post preview tool to verify length before posting.
What is the best LinkedIn post hook formula?
Stat hooks deliver the highest measured engagement lift at 1.67x baseline, followed by story hooks at 1.51x and direct/utility hooks at 1.45x. Imperative hooks ("Stop doing this", "Read this if") deliver 0.02x lift and should be avoided. The hook generator creates variations sorted by archetype.
How do I write a good LinkedIn post if I have no audience yet?
Focus on the structure first, audience second. The same hook formulas, length sweet spot, and CTA patterns work whether you have 100 followers or 100,000. The algorithm gives every post a 3 to 8 hour evaluation window to prove it deserves wider distribution, and structure is what wins that window. Pick one hook archetype (start with stat or story) and publish 5 to 10 posts using the same skeleton before optimizing.
How often should I post on LinkedIn?
Quality matters more than frequency in 2026. The shift from social-graph to interest-graph means a single high-performing post can reach more people than 5 mediocre ones. Most growth-mode creators publish 3 to 5 times per week, but if you are choosing between posting daily with weak hooks or twice a week with strong ones, choose the latter. The LinkedIn algorithm guide covers reach-vs-frequency tradeoffs in detail.
Do hashtags help LinkedIn posts get noticed?
Hashtags have a marginal effect in 2026. Use 3 to 5 niche, relevant hashtags maximum. Avoid generic high-volume tags like #leadership or #motivation, which drown your post in unrelated content. The signal that actually drives reach is dwell time and comment velocity, not hashtag selection.
What is the LinkedIn post structure that gets the most engagement?
The highest-lift skeleton in our dataset is "Feature Deep-Dive Guide" at 4.58x baseline lift. It uses a direct/utility hook, a numbered or step-based body in the 900 to 1,300 character range, and a Resource Bribe CTA. Story-driven skeletons like "Identity Pivot Narrative" (3.48x) and "Full-Circle Reflection" (3.30x) are the strongest narrative options. Browse the full library of viral post templates for tested structures.
How do I make my LinkedIn post format more readable?
Aggressive line breaks (one idea per line), sub-anchors every 3 to 4 lines, and concrete specifics (names, numbers, dates) instead of abstractions. The visual shape of your post under the "see more" cutoff is your second hook. If it looks like a wall of text, readers will not expand.
Can AI write LinkedIn posts that go viral?
Generic AI output does not go viral, because it pattern-matches to the bottom 60% of the corpus. AI trained on viral structures and your own voice can. ViralBrain's LinkedIn post generator is trained on the 30,360-post dataset described in this article and generates voice-matched drafts using the hook formulas and skeletons that show measured engagement lift. ViralBrain offers a free trial available on the pricing page, plus 100+ free tools that require no account.
What is the difference between a viral LinkedIn post and a normal one?
In our dataset, the average viral post earns 535 likes versus 311 for non-viral posts. The structural differences are concentrated in three places: the hook (stat or story versus generic direct), the length (900 to 1,300 chars or 2,500+ versus 300 to 600), and the CTA (Resource Bribe or Specific Question versus generic "What do you think?"). Hit those three, and your post moves from baseline (2.18% viral rate) to the 3% sweet spot range.
Automate your LinkedIn for 30 days
ViralBrain plans, writes, and schedules your LinkedIn content — using official LinkedIn APIs so your account stays safe.
- Official LinkedIn APIs — no risk of ban
- You approve every post before it goes live
- Cancel anytime