Extracting text from 90+ file formats. You tried PyMuPDF for PDFs, Tesseract for OCR, Tika for the rest ... Kreuzberg replaces that stack. Content-hash caching drops repeat extractions to sub-10ms. Qu…

703266531 viral
Document AI2 months ago

LinkedIn Content Strategy & Writing Style
Agents, Graphs, Ontologies
1 person tracking this creator on ViralBrain
André Lindenberg positions himself as a high-signal technical architect operating at the bleeding edge of agentic infrastructure and graph-based systems. His content strategy centers on deep-tier technical teardowns of open-source tooling, where he bypasses marketing fluff to evaluate model architectures, confidential computing primitives, and CI/CD workflows for AI agents. He is notable for his ability to bridge the gap between abstract AI research and hard-nosed engineering implementation, often highlighting how specific "harness" primitives or metadata schemas like lat·md solve the "context drift" inherent in large-scale deployments. By intersecting systemic governance with developer experience, Lindenberg provides a sophisticated roadmap for building sovereign, auditable AI that moves beyond simple API wrappers into robust, graph-integrated production environments.
0
0
260
—
20.1
51
2
Extracting text from 90+ file formats. You tried PyMuPDF for PDFs, Tesseract for OCR, Tika for the rest ... Kreuzberg replaces that stack. Content-hash caching drops repeat extractions to sub-10ms. Qu…
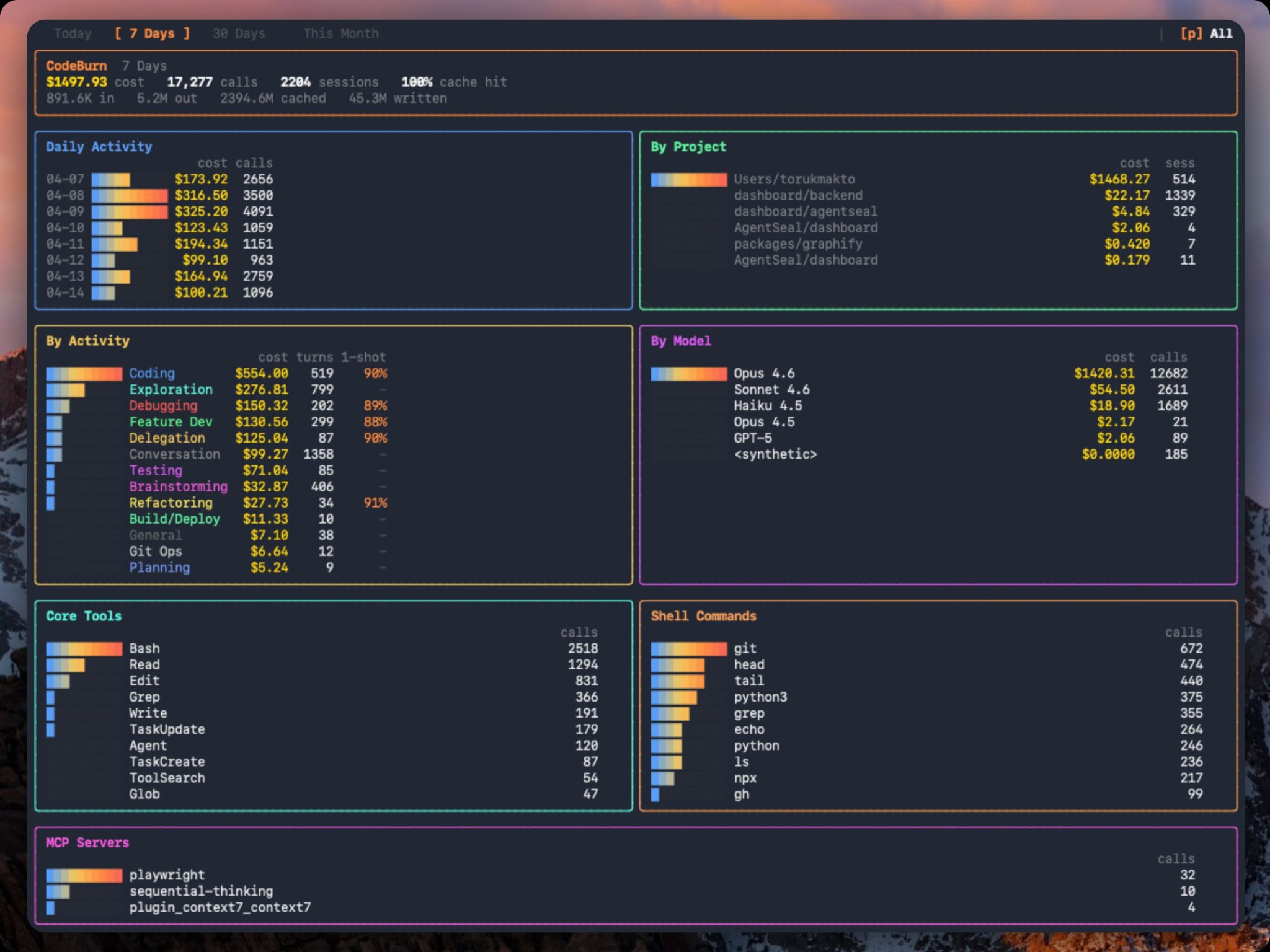
Install codeburn, then run codeburn optimize. That command scans your coding agent sessions for specific waste ... repeated file reads, low read-to-edit ratios, uncapped bash output, unused MCP server…
Five of nine models on this 64GB local LLM cheat sheet are Qwen ... dense 27B flagship at Q8_0, MoE 35B-A3B for speed, dedicated coding, vision, and thinking variants at Q6_K. The rest fills specific…

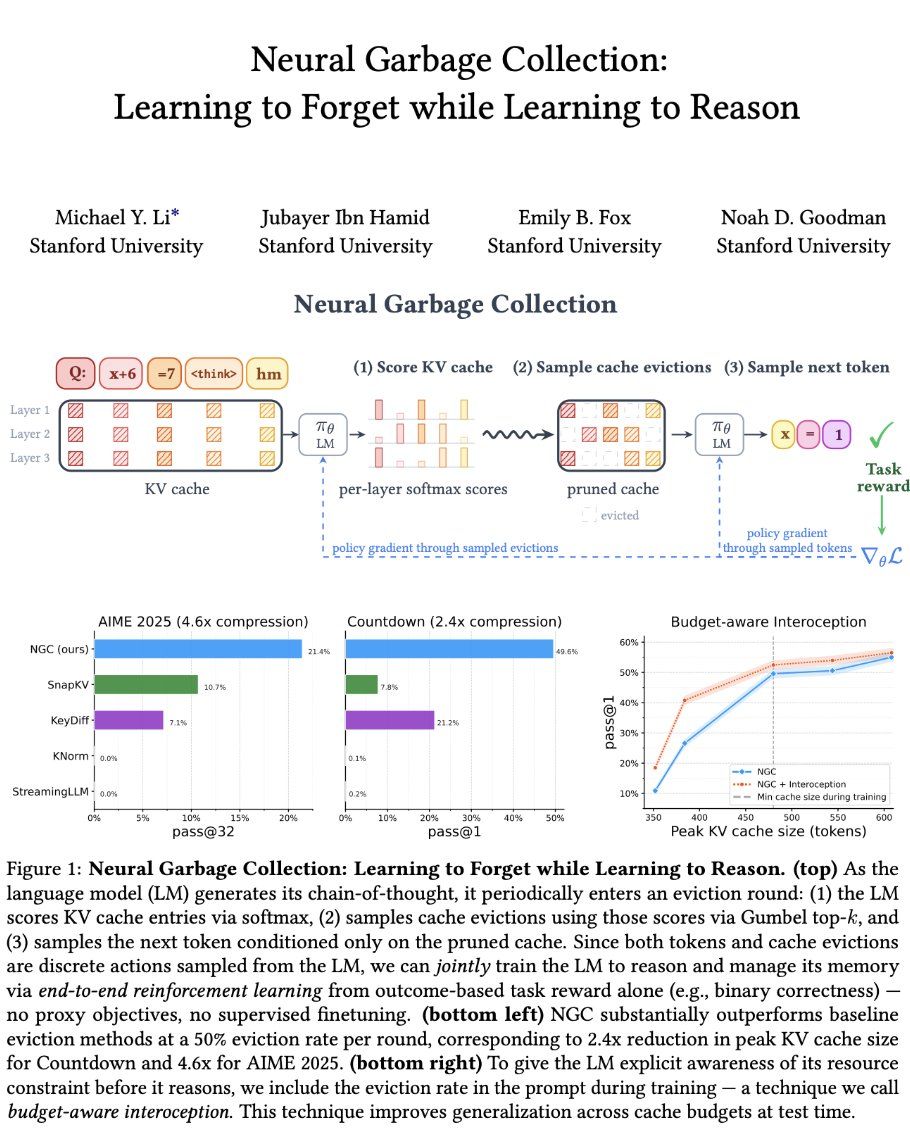
Stanford's Neural Garbage Collection trains a reasoning model to evict its own KV cache blocks using the same RL reward that teaches it to reason. No new modules ... it repurposes existing attention s…
Commercial photogrammetry charges thousands per seat. ODM does the same job from a Docker one-liner … drop JPEGs in a folder, run one command, get georeferenced orthophotos, classified point clouds, D…

Fourteen skills that teach AI coding agents to generate diagrams in Markdown, organized by rendering engine. Nine PlantUML-based skills cover UML, cloud architecture, network topology, security, Archi…
20.1 posts/week
Posts / Week
0.4 days
Days Between Posts
2
Total Posts Analyzed
HIGH
Posting Frequency
259.5%
Avg Engagement Rate
STABLE
Performance Trend
450
Avg Length (Words)
HIGH
Depth Level
ADVANCED
Expertise Level
0.9/10
Uniqueness Score
NO
Question Usage
0.05%
Response Rate
Writing style breakdown
<start of post>
Tracecat is the open-source Tines or Splunk SOAR alternative for security teams. It automates alert triage, evidence collection, and incident response via a visual workflow engine that speaks Python. No proprietary DSL—if you can write a function, you can build a logic gate. Connect to CrowdStrike, SentinelOne, or any webhook-capable tool, then map JSON fields into actionable tickets. The engine handles retries, state persistence, and secret management out of the box. Security operations is a data plumbing problem; Tracecat is the pipe. MIT, 3.2K stars.
#Tracecat #SecOps #Cybersecurity #OpenSource #SOAR #Automation
<end of post>
Sign in to unlock the full writing analysis
Free tools to help you write, score, and benchmark in the same style.
Other creators worth studying alongside André Lindenberg.

Ariel Cohen
Founder @ The Voice Box | Founder-to-founder LinkedIn pipeline coaching for B2B founders | Built $100K in 90 days
470 Viral Score

Henry Shi
Co-Founder of Super.com ($200M+ revenue/year) | AI@Anthropic | LeanAILeaderboard.com | Angel Investor | Forbes U30
171 Viral Score

Penn Frank ⚙️
Co-Founder @StackOptimise
53 Viral Score

Charlie Hills 🦩
I help you (actually) use AI.
75 Viral Score

Nikki Siapno
Eng Manager | ex-Canva | 400k+ audience | Helping you become a great engineer and leader
24 Viral Score
Aditya Sriram
Building GoMarble || AI Agent for paid media marketers; built on your Meta Ads, Google Ads, Shopify, and GA4.
136 Viral Score
ViralBrain plans, writes, and schedules your LinkedIn content — using official LinkedIn APIs so your account stays safe.
Write like André Lindenberg.